
Ich habe Fuse.js in meinem Clipboard-Manager rausgeworfen. 8 Iterationen.
Warum Fuse.js auf Clipboard-Daten scheitert und wie ich Suche in Rust über 8 Iterationen neu geschrieben habe: Same-Field-Matching, Unicode-Wortgrenzen, Scored Merge.
Nutzer haben sich beschwert: Die Suche in Beetroot lieferte Müll. „timeout" passte zu delivery_time_options. „local v" gab 98 Treffer aus 1.106 Einträgen zurück.
Fuse.js war nicht das Problem. Clipboard-Daten waren es. Code-Snippets, Stack Traces, lange URLs: auf Strings mit über 200 Zeichen sind die Buchstaben deiner Query statistisch garantiert irgendwo enthalten. Fuse.js nennt das einen Match.
Zwei Tage. Acht Iterationen. Hier ist jede Sackgasse.
TL;DR:
- Fuse.js liefert auf langen Strings Müll, die Buchstaben streuen über 200+ Zeichen
- Same-Field-Matching hat nicht geholfen. Wortgrenzen haben teilweise geholfen. Field-Priorität war der eigentliche Durchbruch
- Early-Exit hat das monotone Eingrenzen kaputtgemacht (mehr Zeichen getippt → Ergebnisse springen statt sich einzugrenzen)
- Final: Scored Merge, alle Phasen laufen unbedingt, Dedup über bestem Score, Fuzzy ist immer dabei
Der Ausgangspunkt
const fuse = new Fuse(items, {
keys: ['content', 'note', 'source_app', 'source_title'],
threshold: 0.4,
minMatchCharLength: 3,
})
return fuse.search(query) // 🔥 das war's. eine Phase.| Query | Bekommen | Erwartet | Warum |
|---|---|---|---|
timeout | ~40 | 2–5 | Buchstaben t-i-m-e-o-u-t verstreut in delivery_time_options |
local v | 98 | 2–5 | „local" in Fenstertiteln, „v" in allem |
lm st | 71 | 1–3 | „st" matcht „install", „const", „first"… |
port 80 | 13 | 1–3 | „port" in „import" gefunden |
Wie Ditto und CopyQ das machen
Bevor ich irgendwas gebaut habe, habe ich die zwei populärsten Open-Source-Alternativen geprüft.
Ditto: SQLite WHERE mText LIKE '%term%'. Voller Tablescan bei jedem Tastenanschlag. Kein Fuzzy, kein Scoring, kein FTS-Index.
CopyQ: In-Memory QString::contains() pro Item, AND-Logik über Tokens, die an Whitespace gesplittet werden. In 20-ms-Slices gebatcht. Kein Fuzzy, kein Scoring.
Beide haben dieselben Probleme: kein Relevanz-Ranking (alles nach Aktualität sortiert), keine Awareness für Code-Strukturen (LIKE '%port%' matcht „import") und lineare Scans, die bei Größe ausbremsen.
Fuse.js war für Tippfehlertoleranz schon besser. Das Problem war nicht die Baseline, sondern dass Fuzzy-Matching für lange Strings grundsätzlich falsch ist.
Die 8 Iterationen
1. Same-Field-Matching → hat nicht geholfen
Idee: Alle Tokens müssen im selben Feld vorkommen.
tokens.every(t => field.lower.includes(t))"local v" → immer noch 98. Warum? source_title enthielt „So the local path needed loopback-only validati...", sowohl „local" als auch „v" (in „validation") in EINEM Feld. Lange Metadaten-Strings sind der Feind.
2. Wortgrenzen-Matching → teilweise geholfen
Idee: „v" sollte nicht in der Mitte von „validation" matchen.
JavaScripts \b funktioniert nicht für Unicode, kyrillisch und CJK sind alle kaputt:
/\bстд/.test('лм стд нельзя') // false! \b kennt kein KyrillischEine Unicode-bewusste isWordStart() gebaut:
function isWordStart(text: string, pos: number): boolean {
if (pos === 0) return true
const prev = text[pos - 1]
if (!/[\p{L}\p{N}]/u.test(prev)) return true // nach space, _, -
if (/\p{Ll}/u.test(prev) && /\p{Lu}/u.test(text[pos])) return true // camelCase
return false
}| Position | Beispiel | Grenze? |
|---|---|---|
| Nach Leerzeichen | import ▌React | ✓ |
Nach _ | delivery_▌time | ✓ |
| camelCase | local▌Variable | ✓ |
| Mitte des Worts | im▌port | ✗ |
| Kyrillisch | лм ▌стд | ✓ |
"local v" → 78. Besser, aber source_title enthielt beide Wörter weiterhin an legitimen Grenzen.
3. Sauberes Refactor → gleiche Ergebnisse, besserer Code
Code war Patch-auf-Patch, 7 Commits, jeder hat den vorherigen geflickt. In drei saubere Phasen umgeschrieben: zusammenhängender Substring → Word-Start-Tokens → Fuse.js Fuzzy. Aber alle 4 Felder werden weiterhin gleich behandelt.
4. Field-Priorität → der eigentliche Durchbruch
Das Problem war nie der Algorithmus. Es war, Fenster-Metadaten gleichberechtigt mit Clipboard-Inhalt zu behandeln.
const PRIMARY = ['content', 'note'] // was du kopiert hast
const SECONDARY = ['source_app', 'source_title'] // Fenster-MetadatenErst Primary durchsuchen. Nur auf Metadaten zurückfallen, wenn nichts gefunden wurde, strikter Early-Exit:
const p1 = contiguousSearch(items, query, PRIMARY)
if (p1.length > 0) return p1
const p2 = wordStartTokenSearch(items, query, PRIMARY)
if (p2.length > 0) return p2
// Nur wenn Content nichts hat, Metadaten prüfen
const s1 = contiguousSearch(items, query, SECONDARY)
if (s1.length > 0) return s1"local v" → 9 Ergebnisse. Runter von 98. Das source_title-Rauschen war eliminiert, weil die Content-Treffer zuerst gefunden wurden.
Sieben Iterationen, die die Matching-Logik verbessert haben. Der eigentliche Fix? Ein if-Statement. (Diese Early-Exit-Logik würde später eigene Probleme machen, siehe Iteration 6.)
5. Fragment-Highlight → unsichtbare Treffer sichtbar
Bei langen Clips waren Highlights unsichtbar. truncate() zeigte die ersten 100 Zeichen, aber der Treffer konnte an Position 250 sitzen:
// Vorher: immer die ersten 100 Zeichen → Treffer nicht sichtbar
// Nachher: Fenster verschiebt sich auf den Treffer
if (indices[0][0] >= maxLen) {
offset = matchStart - contextBefore
}
// "...needed a local variable for the..." ← hervorgehoben6–7. Early-Exit kaputt → Merged Scoring
Early-Exit klang elegant. Aber es hat das monotone Eingrenzen zerstört, also die Erwartung, dass mehr getippte Zeichen die Ergebnisse eingrenzen:
"thai" → Phase 1 → 6 Ergebnisse
"thai mon" → Phase 1 → 0 → Phase 2 → 1 komplett anderes Ergebnis 😱
Und ein Paradox: bessere Rechtschreibung → weniger Ergebnisse:
"Antropc" → fuzzy → findet "Anthropic" → 3 Ergebnisse
"antrophic" → Phase 1: 1 exakter Treffer → fuzzy übersprungen → 1 Ergebnis 🤔
8. Scored Merge → die finale Architektur
Der Fix war nicht, zwischen Early-Exit und immer-laufen zu wählen. Er war, alles laufen zu lassen, aber jede Phase unterschiedlich zu scoren:
// Alle Phasen laufen unbedingt, jede mit anderem Score
const hits: ScoredHit[] = [
...collectScored(contiguousSearch(items, q, PRIMARY), 1.0),
...collectScored(wordStartTokenSearch(items, q, PRIMARY), 0.75),
...collectScored(contiguousSearch(items, q, SECONDARY), 0.5),
...collectScored(wordStartTokenSearch(items, q, SECONDARY), 0.25),
]
// Dedup: besten Score pro Item behalten
const best = new Map<number, ScoredHit>()
for (const hit of hits) {
const existing = best.get(hit.item.id)
if (!existing || hit.score > existing.score)
best.set(hit.item.id, hit)
}
// Fuzzy läuft immer, fügt aber nur NEUE Items hinzu, die oben nicht gefunden wurden
for (const r of ensureIndex(items).search(query)) {
if (!best.has(r.item.id))
best.set(r.item.id, { item: r.item,
score: Math.max(0.05, 0.15 * (1 - (r.score ?? 1))), ... })
}Warum das funktioniert:
- Keine Early-Exit-Probleme. Jede Phase läuft immer → monotones Eingrenzen garantiert
- Kein Rauschen. Scores steuern Ranking, nicht Filterung. „local" aus
source_titlescort 0.5, derselbe Treffer incontentscort 1.0, Content gewinnt in der Sortierung immer - Fuzzy immer dabei. „Antropc" findet „Anthropic", egal ob exakte Treffer existieren, nur niedriger gerankt
Wie Scored Merge arbeitet
"local v" → Phase 1: 9 exakte Treffer (1.0), Phase 2-4: einige bei 0.75/0.5/0.25
→ Dedup behält Score 1.0 für Content-Treffer → 9 Top-Ergebnisse ✓
"lm st" → Phase 1: 0 → Phase 2: 1 Word-Start (0.75)
→ Phase 5 (fuzzy): fügt Tippfehler-Treffer bei 0.05–0.15 hinzu
"Antropc" → Phasen 1-4: 0 → Phase 5: Fuse.js → "Anthropic" bei 0.05–0.15 ✓
"timeout" → Phase 1: 20+ Substring-Treffer (1.0) → oben in den Ergebnissen
→ niedrigere Phasen laufen weiter, können Content-Treffer aber nicht überholen
Die Score-Tabelle
| Score | Was matcht | Felder |
|---|---|---|
| 1.0 | Exakter Phrase-Substring | content, note |
| 0.75 | Word-Start-Tokens | content, note |
| 0.5 | Exakter Phrase-Substring | window title, app |
| 0.25 | Word-Start-Tokens | window title, app |
| 0.05–0.15 | Fuzzy (Tippfehler) | alle Felder |
Alle Phasen laufen auf jeder Query. Scores steuern Ranking, nicht Filterung.
Vorher → nachher
Auf 1.120 echten Clipboard-Einträgen:
| Query | Vorher | Nachher | Was sich geändert hat |
|---|---|---|---|
local v | 98 | 9 | Metadaten können nicht mehr verschmutzen |
lm st | 71 | 1–2 | „st" matcht „install" nicht mehr |
port 80 | 13 | 1–2 | „port" matcht „import" nicht mehr |
timeout | ~40 | ~8 | Nur exakter Substring |
thai → thai mon | Sprung | Eingrenzen | Monoton ✓ |
Antropc (Tippfehler) | 3 | 3 | Tippfehlertoleranz erhalten |
Benchmark (1.120 Items, 5.000 Query-Runs): 0,76 ms pro Query. Alle Phasen laufen zu lassen verursacht vernachlässigbaren Overhead, die deterministischen Phasen sind einfache Stringoperationen, und der Fuse.js-Index wird gecacht.
In Aktion
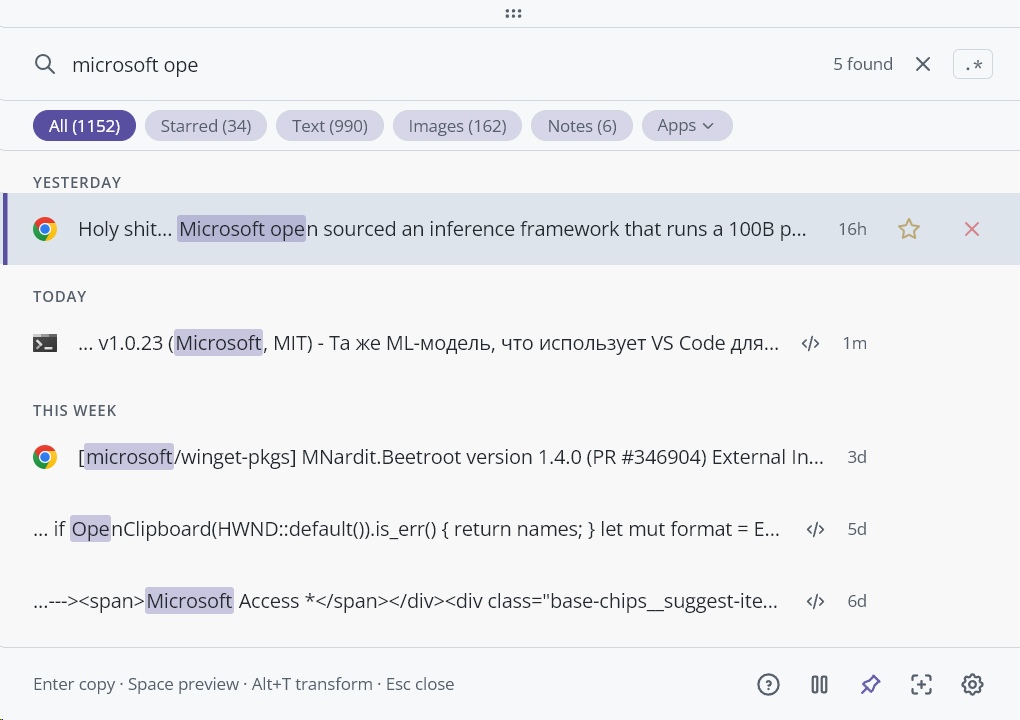
Exakter Treffer: „microsoft ope" findet 5 relevante Einträge mit hervorgehobenen Tokens:
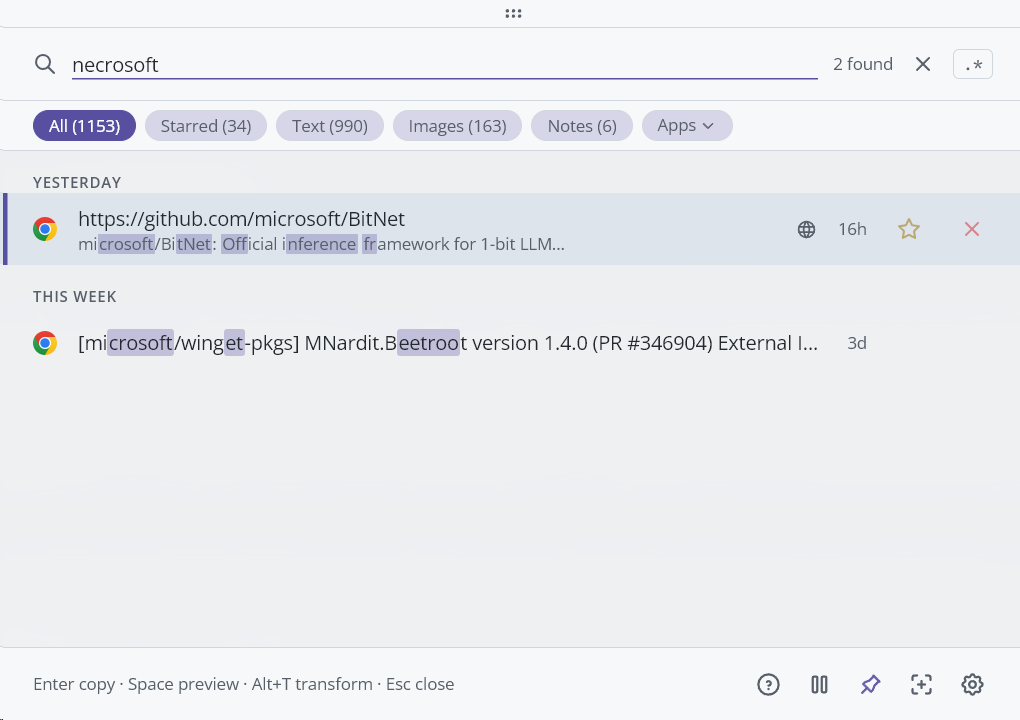
Fuzzy-Tippfehler: „necrosoft" (verschrieben) findet trotzdem Microsoft-Einträge über die Fuzzy-Phase:
Die Highlight-Steuer
Treffer finden sind 3 Zeilen. Zu zeigen, warum etwas gematcht hat, sind 40 Prozent des Codes.
Der schlimmste Bug: Query port import auf import React from 'react', „import" matcht [0,5], „port" matcht [2,5] (es steckt in „import"). Zwei sich überlappende <mark>-Elemente → visueller Glitch. Klassischer Interval-Merge fixt das:
indices.sort((a, b) => a[0] - b[0])
const merged: [number, number][] = []
for (const pair of indices) {
const last = merged[merged.length - 1]
if (last && pair[0] <= last[1] + 1)
last[1] = Math.max(last[1], pair[1]) // overlapping mergen
else
merged.push([pair[0], pair[1]])
}
// [0,5] + [2,5] → [0,5]. +1 mergt auch angrenzende Bereiche.Außerdem: fieldIndices.push(...findAllIndices()) schlug auf 10K-Zeichen-Strings mit RangeError: Maximum call stack size exceeded fehl. Der Spread-Operator expandiert in Funktionsargumente, V8 hat ein Limit. Durch eine explizite Schleife ersetzt.
Was ich gelernt habe
Das Problem waren die Daten, nicht der Algorithmus. Sieben Iterationen haben die Matching-Logik verbessert. Der eigentliche Fix war Field-Priorität: aufhören, Fenstertitel gleichberechtigt mit Content zu behandeln.
Monotones Eingrenzen ist nicht optional. „Mehr getippt → Ergebnisse springen" ist tief desorientierend. Mit Query-Sequenzen testen, nicht mit einzelnen Queries.
Fuzzy ist kein Fallback. Tippfehlertolerante Ergebnisse sollten immer da sein, nur niedrig gerankt. „Fuzzy ODER deterministisch" erzeugt Paradoxa, in denen bessere Rechtschreibung → weniger Ergebnisse.
Patch auf Patch wird in 48 Stunden zu technischer Schuld. Sieben Commits, jeder den vorherigen flickend. Ein sauberes Refactor in Iteration 3 hätte vier Commits gespart. Aber wahrscheinlich brauchte ich die Sackgassen, um das Problem zu verstehen.
