
クリップボードマネージャーから Fuse.js を一掃しました。8 イテレーションかかりました。
Fuse.js がクリップボードデータで失敗する理由と、8 イテレーションをかけて Rust で検索を書き直した話: 同フィールドマッチング、Unicode 単語境界、スコア付きマージ。
ユーザーから苦情が続きました。Beetroot の検索がゴミを返すと。「timeout」が delivery_time_options にマッチする。「local v」で 1,106 エントリーから 98 件が返ってくる。
問題は Fuse.js ではなく、クリップボードデータでした。コードスニペット、スタックトレース、長い URL、200 文字以上の文字列上では、クエリの文字は 統計的にどこかに含まれることが保証されています。Fuse.js はそれをマッチと呼ぶのです。
2 日間。8 イテレーション。すべての遠回りを書きます。
TL;DR:
- Fuse.js は長い文字列でゴミを返す。文字が 200 文字以上に散らばってマッチする
- 同フィールドマッチングは効かなかった。単語境界は部分的に効いた。フィールド優先順位 が本当のブレイクスルー
- early-exit は単調な絞り込みを壊す (文字を多く打つほど結果が ジャンプ する、絞り込まれない)
- 最終形: スコア付きマージ、すべてのフェーズが無条件に走り、ベストスコアで重複排除し、ファジーは常に存在する
出発点
const fuse = new Fuse(items, {
keys: ['content', 'note', 'source_app', 'source_title'],
threshold: 0.4,
minMatchCharLength: 3,
})
return fuse.search(query) // 🔥 これだけ。1 フェーズ。| クエリ | 取得 | 期待 | なぜ |
|---|---|---|---|
timeout | ~40 | 2–5 | 文字 t-i-m-e-o-u-t が delivery_time_options に散在 |
local v | 98 | 2–5 | 「local」がウィンドウタイトルに、「v」が あらゆる場所 に |
lm st | 71 | 1–3 | 「st」が「install」「const」「first」にマッチ |
port 80 | 13 | 1–3 | 「port」が「import」内部で見つかる |
Ditto と CopyQ はどうしているか
何かを作る前に、人気のあるオープンソース代替 2 つを確認しました。
Ditto:SQLite の WHERE mText LIKE '%term%'。キーストロークごとにテーブル全スキャン。ファジーなし、スコアリングなし、FTS インデックスなし。
CopyQ:メモリ内の QString::contains() をアイテムごとに、空白で分割したトークン間で AND ロジック。20 ms スライスでバッチ処理。ファジーなし、スコアリングなし。
どちらも同じ問題を抱えています。関連度ランキングなし (すべて新しい順)、コード構造への意識なし (LIKE '%port%' は「import」にマッチする)、規模が大きくなると遅くなる線形スキャン。
Fuse.js はタイポ耐性ですでに上回っていました。問題はベースラインではなく、ファジーマッチングが長文に対して根本的に間違っているという点です。
8 イテレーション
1. 同フィールドマッチング → 効かなかった
アイデア: すべてのトークンを同じフィールドに要求する。
tokens.every(t => field.lower.includes(t))"local v" → 依然として 98 件。なぜ? source_title に「So the local path needed loopback-only validati...」があり、「local」と (「validation」内の) 「v」が 1 つのフィールドに同時に存在していました。長いメタデータ文字列は敵です。
2. 単語境界マッチング → 部分的に効いた
アイデア: 「v」が「validation」の中間にマッチすべきではない。
JavaScript の \b は Unicode に対応していません。キリル文字も CJK もすべて壊れます。
/\bстд/.test('лм стд нельзя') // false! \b はキリル文字を知らないUnicode 対応の isWordStart() を作りました。
function isWordStart(text: string, pos: number): boolean {
if (pos === 0) return true
const prev = text[pos - 1]
if (!/[\p{L}\p{N}]/u.test(prev)) return true // space, _, - のあと
if (/\p{Ll}/u.test(prev) && /\p{Lu}/u.test(text[pos])) return true // camelCase
return false
}| 位置 | 例 | 境界? |
|---|---|---|
| スペースのあと | import ▌React | ✓ |
_ のあと | delivery_▌time | ✓ |
| camelCase | local▌Variable | ✓ |
| 単語の途中 | im▌port | ✗ |
| キリル文字 | лм ▌стд | ✓ |
"local v" → 78 件。改善されましたが、source_title には依然として両方の単語が正当な境界で含まれていました。
3. クリーンなリファクタ → 結果は同じ、コードが良くなった
コードはパッチの上にパッチでした。7 コミット、それぞれが前を継ぎ足し。3 つのきれいなフェーズに書き直しました: 連続する部分文字列 → 単語先頭トークン → Fuse.js ファジー。しかし依然として 4 フィールドを同等に扱っていました。
4. フィールド優先順位 → 本当のブレイクスルー
問題は決してアルゴリズムではありませんでした。ウィンドウメタデータをクリップボード内容と同等に扱っていることでした。
const PRIMARY = ['content', 'note'] // コピーした内容
const SECONDARY = ['source_app', 'source_title'] // ウィンドウメタデータまず Primary を検索。何も見つからない場合のみメタデータにフォールバック、厳格な early-exit です。
const p1 = contiguousSearch(items, query, PRIMARY)
if (p1.length > 0) return p1
const p2 = wordStartTokenSearch(items, query, PRIMARY)
if (p2.length > 0) return p2
// content に何もない場合のみメタデータをチェック
const s1 = contiguousSearch(items, query, SECONDARY)
if (s1.length > 0) return s1"local v" → 9 件。 98 から減りました。content が先に見つかるので source_title のノイズが排除されました。
7 イテレーションのマッチングロジック改善。本当の修正は? 1 つの if 文。(この early-exit ロジックは後に独自の問題を引き起こしました、イテレーション 6 を参照。)
5. フラグメントハイライト → 見えないマッチを見えるように
長いクリップではハイライトが見えませんでした。truncate() は最初の 100 文字を表示しますが、マッチは位置 250 にあるかもしれません。
// 以前: 常に最初の 100 文字 → マッチが見えない
// 以後: ウィンドウがマッチ位置にシフト
if (indices[0][0] >= maxLen) {
offset = matchStart - contextBefore
}
// "...needed a local variable for the..." ← ハイライト6–7. early-exit が壊れる → マージスコアリングへ
early-exit はエレガントに見えました。しかし 単調な絞り込み を壊しました。文字を多く打つと結果が絞られるという期待です。
"thai" → Phase 1 → 6 件
"thai mon" → Phase 1 → 0 → Phase 2 → 完全に異なる 1 件 😱
そしてパラドックス: スペルが正しいほど結果が少ない。
"Antropc" → ファジー → 「Anthropic」を見つける → 3 件
"antrophic" → Phase 1: 1 件の完全一致 → ファジースキップ → 1 件 🤔
8. スコア付きマージ → 最終アーキテクチャ
修正は early-exit と always-run のどちらかを選ぶことではありませんでした。全部走らせるが、各フェーズに異なるスコアを付ける ことでした。
// すべてのフェーズが無条件に実行され、それぞれ異なるスコア
const hits: ScoredHit[] = [
...collectScored(contiguousSearch(items, q, PRIMARY), 1.0),
...collectScored(wordStartTokenSearch(items, q, PRIMARY), 0.75),
...collectScored(contiguousSearch(items, q, SECONDARY), 0.5),
...collectScored(wordStartTokenSearch(items, q, SECONDARY), 0.25),
]
// 重複排除: アイテムごとに最高スコアを保持
const best = new Map<number, ScoredHit>()
for (const hit of hits) {
const existing = best.get(hit.item.id)
if (!existing || hit.score > existing.score)
best.set(hit.item.id, hit)
}
// ファジーは常に走るが、上で見つかっていない新規アイテムだけを追加
for (const r of ensureIndex(items).search(query)) {
if (!best.has(r.item.id))
best.set(r.item.id, { item: r.item,
score: Math.max(0.05, 0.15 * (1 - (r.score ?? 1))), ... })
}なぜこれが機能するのか:
- early-exit の問題なし。 すべてのフェーズが常に走る → 単調な絞り込みが保証される
- ノイズなし。 スコアはランキングを制御し、フィルタリングはしない。
source_titleの「local」は 0.5、contentの同じマッチは 1.0、ソート順では content が常に勝つ - ファジーは常に存在する。 完全一致があってもなくても「Antropc」は「Anthropic」を見つけられる、ただし下位にランクされるだけ
スコア付きマージの動き
"local v" → Phase 1: 完全一致 9 件 (1.0)、Phase 2-4: 0.75/0.5/0.25 で数件
→ 重複排除で content マッチのスコア 1.0 を保持 → トップ 9 件 ✓
"lm st" → Phase 1: 0 → Phase 2: 単語先頭 1 件 (0.75)
→ Phase 5 (ファジー): タイポマッチを 0.05–0.15 で追加
"Antropc" → Phase 1-4: 0 → Phase 5: Fuse.js → 「Anthropic」を 0.05–0.15 で ✓
"timeout" → Phase 1: 部分文字列マッチ 20 件以上 (1.0) → 結果の上位
→ 下位フェーズも走るが content マッチを抜けない
スコア表
| スコア | マッチ対象 | フィールド |
|---|---|---|
| 1.0 | 完全フレーズの部分文字列 | content, note |
| 0.75 | 単語先頭トークン | content, note |
| 0.5 | 完全フレーズの部分文字列 | window title, app |
| 0.25 | 単語先頭トークン | window title, app |
| 0.05–0.15 | ファジー (タイポ) | すべてのフィールド |
すべてのフェーズはどのクエリでも走ります。スコアはランキングを制御し、フィルタリングしません。
前 → 後
実際のクリップボード 1,120 エントリーで:
| クエリ | 前 | 後 | 何が変わったか |
|---|---|---|---|
local v | 98 | 9 | メタデータが汚染できない |
lm st | 71 | 1–2 | 「st」が「install」にマッチしない |
port 80 | 13 | 1–2 | 「port」が「import」にマッチしない |
timeout | ~40 | ~8 | 完全部分文字列のみ |
thai → thai mon | ジャンプ | 絞り込み | 単調 ✓ |
Antropc (タイポ) | 3 | 3 | タイポ耐性は維持 |
ベンチマーク (1,120 アイテム、5,000 回のクエリ実行): クエリあたり 0.76 ms。すべてのフェーズを走らせても無視できるオーバーヘッドです。決定論的フェーズは単純な文字列操作で、Fuse.js のインデックスはキャッシュされています。
動作中
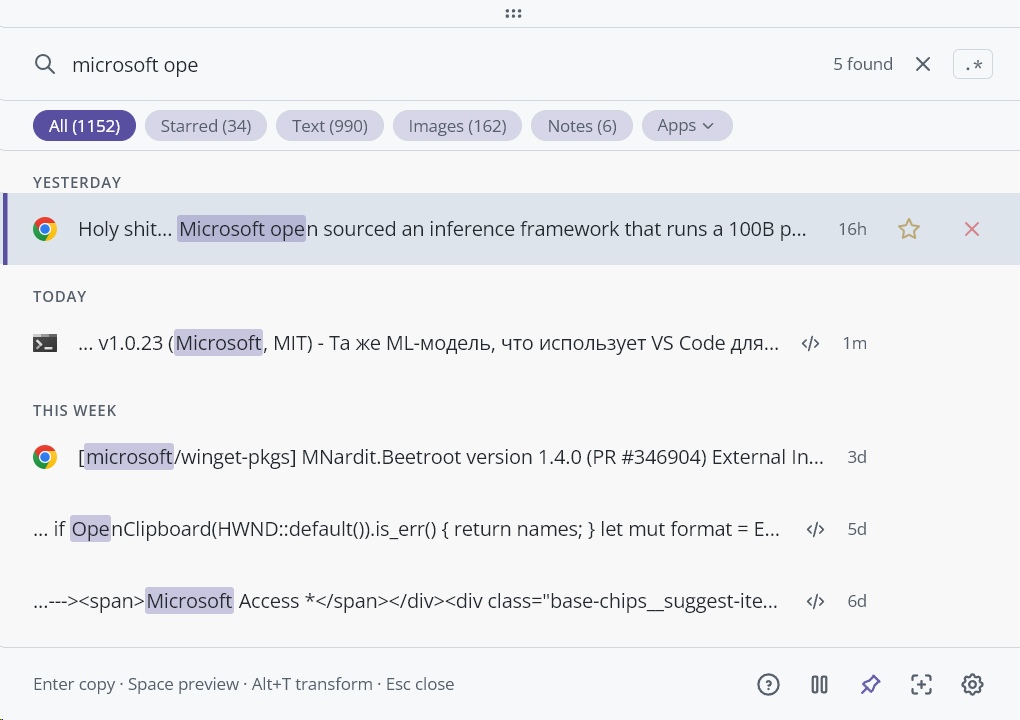
完全一致、「microsoft ope」がハイライト付きで関連 5 件を見つけます。
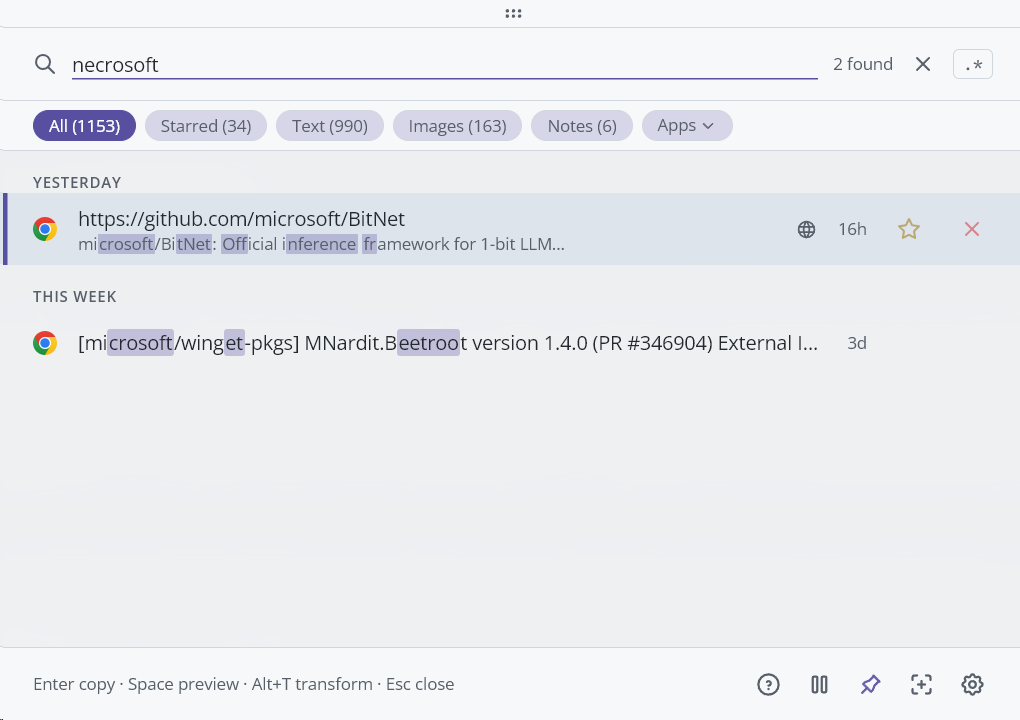
ファジーなタイポ、「necrosoft」(誤記) でもファジーフェーズで Microsoft 関連を見つけます。
ハイライトの税
マッチを見つけるのは 3 行。なぜ マッチしたかを示すのにコードの 40 % です。
最悪のバグ: クエリ port import を import React from 'react' に対して実行すると、「import」は [0,5] でマッチし、「port」は [2,5] でマッチ (「import」の内部にあるため)。重なる <mark> 要素が 2 つ → 視覚的なグリッチ。古典的な区間マージで修正します。
indices.sort((a, b) => a[0] - b[0])
const merged: [number, number][] = []
for (const pair of indices) {
const last = merged[merged.length - 1]
if (last && pair[0] <= last[1] + 1)
last[1] = Math.max(last[1], pair[1]) // 重複をマージ
else
merged.push([pair[0], pair[1]])
}
// [0,5] + [2,5] → [0,5]。+1 で隣接範囲もマージ。そして: fieldIndices.push(...findAllIndices()) が 1 万文字の文字列で RangeError: Maximum call stack size exceeded を出しました。スプレッド演算子は関数引数に展開され、V8 には上限があります。明示的なループに置き換えました。
学んだこと
問題はデータであって、アルゴリズムではなかった。 7 イテレーションでマッチングロジックを改善しました。本当の修正はフィールド優先順位、ウィンドウタイトルを content と同等に扱うのをやめることでした。
単調な絞り込みは任意ではない。 「多く打ったのに結果がジャンプする」は深く混乱させます。個別のクエリではなくクエリの シーケンス でテストしてください。
ファジーはフォールバックではない。 タイポ耐性のある結果は常に存在し、低くランクされるだけであるべきです。「ファジー OR 決定論的」はパラドックスを生みます。スペルが正しいほど結果が少なくなります。
パッチオンパッチは 48 時間で負債になる。 7 コミットそれぞれが前を継ぎ足し。イテレーション 3 でクリーンにリファクタしていたら 4 コミットを節約できました。ただ、おそらくその遠回りが問題空間を理解するのに必要だったのです。
