
Beetroot v1.5.1: ML-Code-Erkennung und Suche, die wirklich funktioniert
Beetroot v1.5.1: VS Codes TensorFlow.js-Modell erkennt 54 Sprachen. Neu geschriebene Suchengine. 'local v' liefert 9 Treffer statt 98.
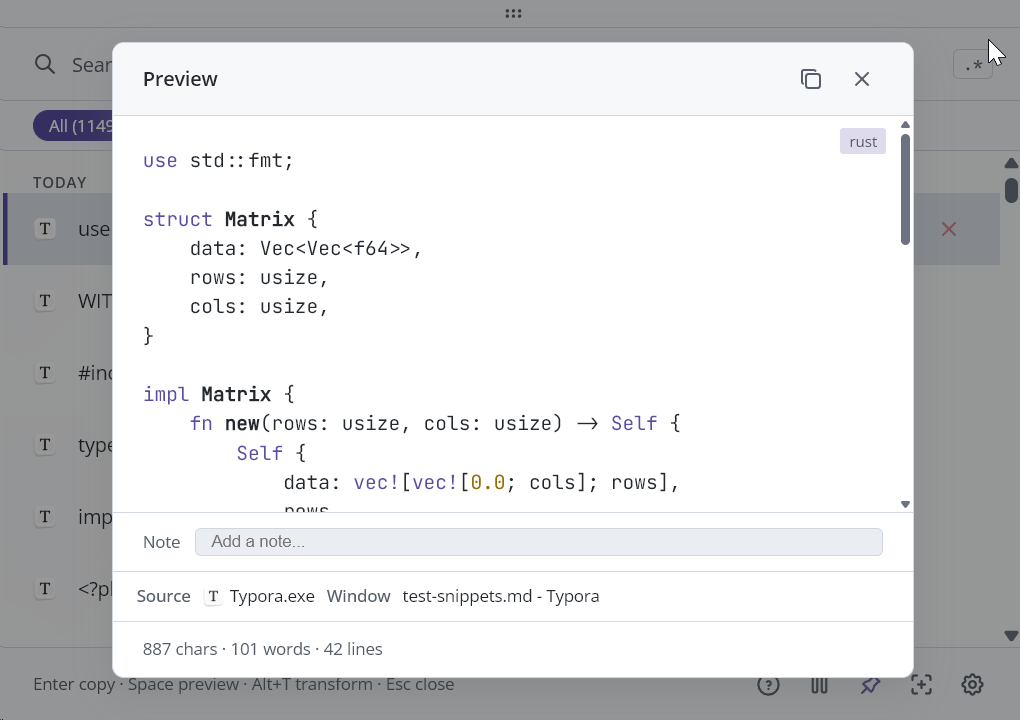
Zwei Dinge an Beetroot haben mich schon länger gestört. Erstens: du kopierst ein Rust-Struct, öffnest die Vorschau, und es wird als C gehighlightet. Oder schlimmer: als Plain Text. Die Code-Erkennung war ein Stapel Regex-Patterns, der etwa fünf Sprachen kannte und bei allem anderen falsch riet.
Zweitens: Eine Suche nach "local v" lieferte 98 Treffer aus 1.100 Clipboard-Einträgen. "port 80" matchte "import", weil "port" ein Substring von "import" ist. Die Fuzzy-Search-Library tat genau, was Fuzzy Search tut, nur leider auf der falschen Art von Daten.
v1.5.1 behebt beides.
Auf einen Blick:
- ML-Sprachen-Erkennung: 54 Programmiersprachen, dasselbe Modell wie VS Code
- Neu geschriebene Suche: "local v" → 9 Treffer statt 98
- Unicode-Wortgrenzen: "port" matcht nicht mehr in "import"
- Fragment-Vorschau: lange Clips zeigen, wo der Match liegt, statt der ersten 100 Zeichen
- Bug-Fixes: Quell-App-Tracking, Object-Literal-Erkennung
Dein Rust-Code sollte nicht als C gehighlightet werden
Die alte Erkennung war eine Funktion namens looksLikeCode(), eine Liste von Keywords wie function, const, class, def. Wenn dein Code eines davon enthielt, wurde es gehighlightet. Wenn nicht, Plain Text. Das funktionierte für JavaScript und Python. Bei allem anderen versagte es.
Rust ohne fn main? Plain Text. Go-Interfaces? Manchmal falsch erkannt. Swift? Plain Text. Ruby? Plain Text. PHP ohne <?php am Anfang? Du ahnst es.
Die neue Erkennung nutzt @vscode/vscode-languagedetection: dasselbe TensorFlow.js-Modell, das VS Code benutzt, wenn du eine Untitled-Datei öffnest und es rät, in welcher Sprache du schreibst. Trainiert auf Millionen GitHub-Dateien, identifiziert 54 Programmiersprachen.
| Sprache | Vorher | Nachher |
|---|---|---|
| Rust | C oder Plain Text | Rust |
| Go | falsch erkannt | Go |
| Swift | Plain Text | Swift |
| Ruby | Plain Text | Ruby |
PHP (ohne <?php) | Plain Text | PHP |
{ key: value } | JSON | JavaScript |
Das Modell ist unter 1 MB, läuft komplett lokal in der App, keine Cloud-Calls, keine API-Keys. Beim ersten Lauf dauert das Laden ~200 ms, danach 10–50 ms pro Erkennung mit Caching.
Eine Sache, mit der ich nicht gerechnet hatte: { name: "foo", count: 42 }. Ist das JSON oder JavaScript? Die alte Regex sagte JSON, da es Klammern und Doppelpunkte hat. Das ML-Modell erkennt JavaScript-Object-Syntax. Eine Kleinigkeit, aber sie sorgt dafür, dass deine JS-Snippets endlich die richtigen Farben bekommen.
Suche, die nicht alles zurückgibt
Ich habe einen ganzen Artikel über das Suche-Rewrite geschrieben, acht Iterationen, jeder Irrweg dokumentiert. Die Kurzfassung:
Fuse.js ist eine großartige Fuzzy-Search-Library. Für kurze Strings: Dateinamen, Kontakte, Menüeinträge. Clipboard-Einträge sind anders: Code-Blöcke, Stack Traces, URLs, oft 200+ Zeichen. Auf so langen Strings ist es statistisch wahrscheinlich, dass die Buchstaben deiner Query irgendwo verteilt im Text auftauchen. Fuse.js wertet das als Match. Deshalb lieferte "local v" 98 Treffer.
Der Fix: ein 5-phasiges Scoring-System. Exakte Substring-Matches im Clipboard-Inhalt ranken am höchsten. Wortgrenzen-Matches kommen als Nächstes. Window-Titel und App-Namen ranken niedriger. Fuzzy-Matching (für Tippfehler) kommt zuletzt. Alles wird dedupliziert, jeder Eintrag behält nur seinen besten Score.
| Query | Vorher | Nachher |
|---|---|---|
local v | 98 | 9 |
port 80 | 13 | 1–2 |
lm st | 71 | 1–2 |
timeout | ~40 | ~8 |
"port" matcht nicht mehr in "import", weil die Suche jetzt Unicode-bewusste Wortgrenzen nutzt. Sie weiß, dass das "port" in "import" kein Wortanfang ist und ignoriert es. Dieselbe Logik funktioniert für Kyrillisch, camelCase und Underscores.
Und für lange Clips: die Vorschau zeigt jetzt, wo der Match liegt, indem das sichtbare Fenster zum passenden Fragment verschoben wird, statt immer die ersten 100 Zeichen anzuzeigen, in denen der Match womöglich gar nicht zu sehen ist.
Bug-Fixes
Quell-App-Tracking: nach dem Aufwachen aus dem Sleep zeigten alle neuen Clips Beetroot als Quell-App, statt des Fensters, aus dem du tatsächlich kopiert hast. Der Clipboard-Monitor feuerte denselben Inhalt erneut als "neues" Event und resettete die Quelle. Behoben durch Content-Deduplizierung.
JS/TS-Object-Literals: { name: "foo", count: 42 } wurde gar nicht als Code erkannt (kein function- oder class-Keyword). Wird jetzt korrekt erkannt und gehighlightet.
Update
Beetroot bietet das Update automatisch an. Oder v1.5.1 von GitHub herunterladen.
