
I Mass-Replaced Fuse.js in My Clipboard Manager. It Took 8 Iterations.
Why Fuse.js fails on clipboard data and how I rewrote search in Rust over 8 iterations: same-field matching, Unicode word boundaries, scored merge.
Users kept complaining: search in Beetroot returned garbage. "timeout" matched delivery_time_options. "local v" returned 98 results out of 1,106 entries.
Fuse.js wasn't the problem. Clipboard data was. Code snippets, stack traces, long URLs — on 200+ character strings, the letters of your query are statistically guaranteed to appear somewhere. Fuse.js calls that a match.
Two days. Eight iterations. Here's every wrong turn.
TL;DR:
- Fuse.js produces garbage on long strings — the letters scatter-match across 200+ characters
- Same-field matching didn't help. Word boundaries helped partially. Field priority was the real breakthrough
- Early-exit broke monotonic narrowing (more characters typed → results jump instead of narrowing)
- Final: scored merge — all phases run unconditionally, dedup by best score, fuzzy always present
The starting point
const fuse = new Fuse(items, {
keys: ['content', 'note', 'source_app', 'source_title'],
threshold: 0.4,
minMatchCharLength: 3,
})
return fuse.search(query) // 🔥 that's it. one phase.| Query | Got | Expected | Why |
|---|---|---|---|
timeout | ~40 | 2–5 | Letters t-i-m-e-o-u-t scattered in delivery_time_options |
local v | 98 | 2–5 | "local" in window titles, "v" in everything |
lm st | 71 | 1–3 | "st" matches "install", "const", "first"... |
port 80 | 13 | 1–3 | "port" found inside "import" |
How Ditto and CopyQ do it
Before building anything, I checked the two most popular open-source alternatives.
Ditto — SQLite WHERE mText LIKE '%term%'. Full table scan on every keystroke. No fuzzy, no scoring, no FTS index.
CopyQ — in-memory QString::contains() per item, AND logic across whitespace-split tokens. Batched in 20ms slices. No fuzzy, no scoring.
Both share the same problems: no relevance ranking (everything sorted by recency), no awareness of code structure (LIKE '%port%' matches "import"), and linear scans that slow down at scale.
Fuse.js was already better for typo tolerance. The problem wasn't the baseline — it was that fuzzy matching is fundamentally wrong for long strings.
The 8 iterations
1. Same-field matching → didn't help
Idea: require all tokens in the same field.
tokens.every(t => field.lower.includes(t))"local v" → still 98. Why? source_title had "So the local path needed loopback-only validati..." — both "local" and "v" (in "validation") in ONE field. Long metadata strings are the enemy.
2. Word-boundary matching → partially helped
Idea: "v" shouldn't match the middle of "validation."
JavaScript \b doesn't work for Unicode — Cyrillic, CJK all broken:
/\bстд/.test('лм стд нельзя') // false! \b doesn't know CyrillicBuilt a Unicode-aware isWordStart():
function isWordStart(text: string, pos: number): boolean {
if (pos === 0) return true
const prev = text[pos - 1]
if (!/[\p{L}\p{N}]/u.test(prev)) return true // after space, _, -
if (/\p{Ll}/u.test(prev) && /\p{Lu}/u.test(text[pos])) return true // camelCase
return false
}| Position | Example | Boundary? |
|---|---|---|
| After space | import ▌React | ✓ |
After _ | delivery_▌time | ✓ |
| camelCase | local▌Variable | ✓ |
| Mid-word | im▌port | ✗ |
| Cyrillic | лм ▌стд | ✓ |
"local v" → 78. Better, but source_title still contained both words at legitimate boundaries.
3. Clean refactor → same results, better code
Code was patch-on-patch — 7 commits, each patching the previous. Rewrote into three clean phases: contiguous substring → word-start tokens → Fuse.js fuzzy. But still treating all 4 fields equally.
4. Field priority → the real breakthrough
The problem was never the algorithm. It was treating window metadata as equal to clipboard content.
const PRIMARY = ['content', 'note'] // what you copied
const SECONDARY = ['source_app', 'source_title'] // window metadataSearch primary first. Only fall back to metadata if nothing found — strict early-exit:
const p1 = contiguousSearch(items, query, PRIMARY)
if (p1.length > 0) return p1
const p2 = wordStartTokenSearch(items, query, PRIMARY)
if (p2.length > 0) return p2
// Only if content has nothing — check metadata
const s1 = contiguousSearch(items, query, SECONDARY)
if (s1.length > 0) return s1"local v" → 9 results. Down from 98. The source_title noise was eliminated because content matches were found first.
Seven iterations improving matching logic. The real fix? One if statement. (This early-exit logic would later cause its own problems — see iteration 6.)
5. Fragment highlight → invisible matches made visible
For long clips, highlights were invisible. truncate() showed the first 100 chars, but the match could be at position 250:
// Before: always first 100 chars → match not visible
// After: window shifts to the match
if (indices[0][0] >= maxLen) {
offset = matchStart - contextBefore
}
// "...needed a local variable for the..." ← highlighted6–7. Early-exit broke → merged scoring
Early-exit seemed elegant. But it broke monotonic narrowing — the expectation that typing more characters narrows results:
"thai" → Phase 1 → 6 results
"thai mon" → Phase 1 → 0 → Phase 2 → 1 completely different result 😱
And a paradox: better spelling → fewer results:
"Antropc" → fuzzy → finds "Anthropic" → 3 results
"antrophic" → Phase 1: 1 exact match → fuzzy skipped → 1 result 🤔
8. Scored merge → the final architecture
The fix wasn't choosing between early-exit and always-run. It was running everything, but scoring each phase differently:
// All phases run unconditionally, each at a different score
const hits: ScoredHit[] = [
...collectScored(contiguousSearch(items, q, PRIMARY), 1.0),
...collectScored(wordStartTokenSearch(items, q, PRIMARY), 0.75),
...collectScored(contiguousSearch(items, q, SECONDARY), 0.5),
...collectScored(wordStartTokenSearch(items, q, SECONDARY), 0.25),
]
// Dedup: keep best score per item
const best = new Map<number, ScoredHit>()
for (const hit of hits) {
const existing = best.get(hit.item.id)
if (!existing || hit.score > existing.score)
best.set(hit.item.id, hit)
}
// Fuzzy always runs — but only adds NEW items not found above
for (const r of ensureIndex(items).search(query)) {
if (!best.has(r.item.id))
best.set(r.item.id, { item: r.item,
score: Math.max(0.05, 0.15 * (1 - (r.score ?? 1))), ... })
}Why this works:
- No early-exit problems. Every phase always runs → monotonic narrowing guaranteed
- No noise. Scores control ranking, not filtering. "local" from
source_titlescores 0.5, the same match incontentscores 1.0 — content always wins in sort order - Fuzzy always present. "Antropc" finds "Anthropic" whether or not exact matches exist — just ranked lower
How scored merge works
"local v" → Phase 1: 9 exact hits (1.0), Phase 2-4: some at 0.75/0.5/0.25
→ dedup keeps score 1.0 for content matches → 9 top results ✓
"lm st" → Phase 1: 0 → Phase 2: 1 word-start (0.75)
→ Phase 5 (fuzzy): adds typo hits at 0.05–0.15
"Antropc" → Phases 1-4: 0 → Phase 5: Fuse.js → "Anthropic" at 0.05–0.15 ✓
"timeout" → Phase 1: 20+ substring hits (1.0) → top of results
→ lower phases still run but can't outrank content matches
The score table
| Score | What matches | Fields |
|---|---|---|
| 1.0 | Exact phrase substring | content, note |
| 0.75 | Word-start tokens | content, note |
| 0.5 | Exact phrase substring | window title, app |
| 0.25 | Word-start tokens | window title, app |
| 0.05–0.15 | Fuzzy (typos) | all fields |
All phases run on every query. Scores control ranking, not filtering.
Before → after
On 1,120 real clipboard entries:
| Query | Before | After | What changed |
|---|---|---|---|
local v | 98 | 9 | Metadata can't pollute |
lm st | 71 | 1–2 | "st" won't match "install" |
port 80 | 13 | 1–2 | "port" won't match "import" |
timeout | ~40 | ~8 | Exact substring only |
thai → thai mon | Jump | Narrow | Monotonic ✓ |
Antropc (typo) | 3 | 3 | Typo tolerance kept |
Benchmark (1,120 items, 5,000 query runs): 0.76ms per query. Running all phases adds negligible overhead — the deterministic phases are simple string operations, and the Fuse.js index is cached.
In action
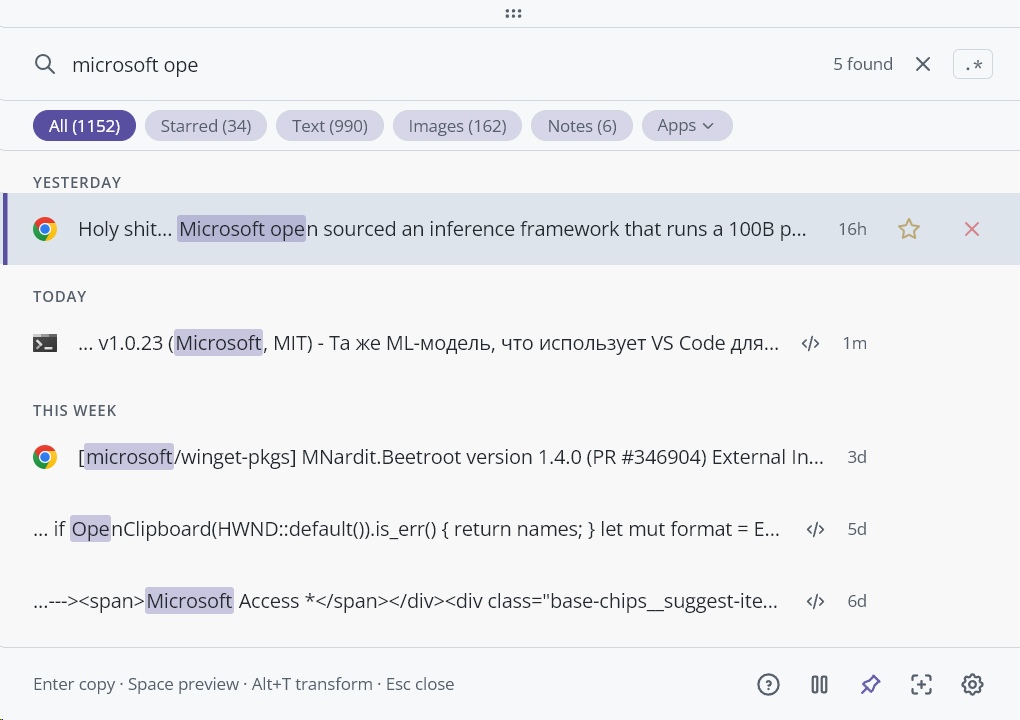
Exact match — "microsoft ope" finds 5 relevant entries with highlighted tokens:
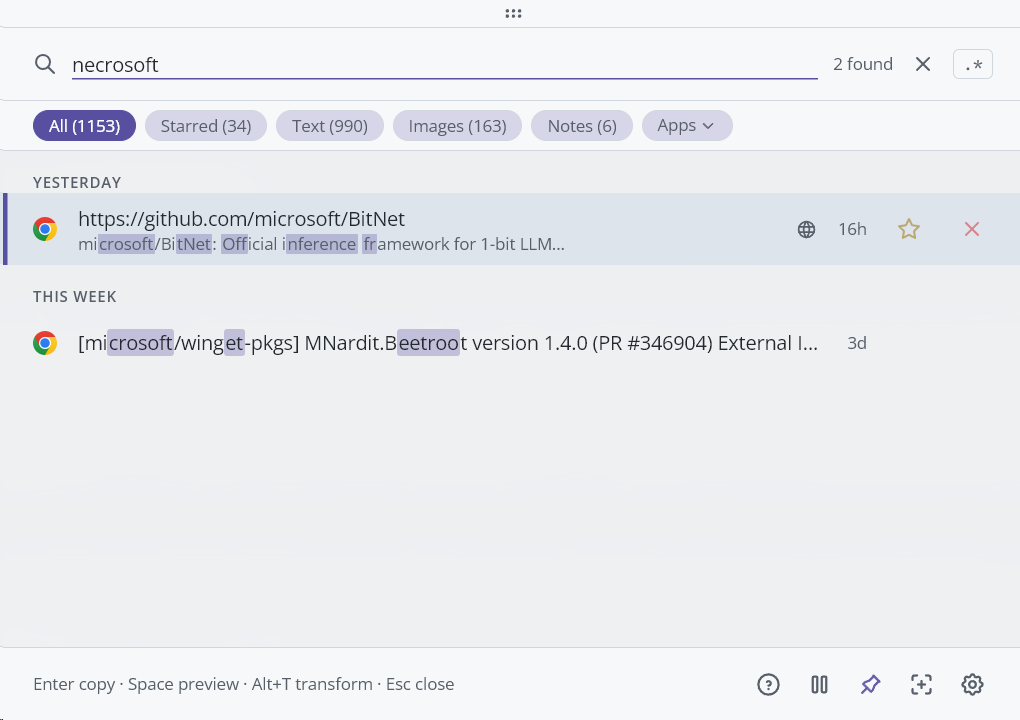
Fuzzy typo — "necrosoft" (misspelled) still finds Microsoft entries via fuzzy phase:
The highlight tax
Finding matches is 3 lines. Showing why something matched — 40% of the code.
The worst bug: query port import on import React from 'react' — "import" matches [0,5], "port" matches [2,5] (it's inside "import"). Two overlapping <mark> elements → visual glitch. Classic interval merge fixes it:
indices.sort((a, b) => a[0] - b[0])
const merged: [number, number][] = []
for (const pair of indices) {
const last = merged[merged.length - 1]
if (last && pair[0] <= last[1] + 1)
last[1] = Math.max(last[1], pair[1]) // merge overlapping
else
merged.push([pair[0], pair[1]])
}
// [0,5] + [2,5] → [0,5]. +1 merges adjacent ranges too.Also: fieldIndices.push(...findAllIndices()) hit RangeError: Maximum call stack size exceeded on 10K-char strings. Spread operator expands into function arguments — V8 has a limit. Replaced with explicit loop.
What I learned
The problem was the data, not the algorithm. Seven iterations improved matching logic. The real fix was field priority — stop treating window titles as equal to content.
Monotonic narrowing is not optional. "Typed more → results jump" is deeply disorienting. Test with query sequences, not individual queries.
Fuzzy is not a fallback. Typo-tolerant results should always be present, just ranked low. "Fuzzy OR deterministic" creates paradoxes where better spelling → fewer results.
Patch-on-patch is debt in 48 hours. Seven commits each patching the previous. A clean refactor at iteration 3 would have saved four commits. But I probably needed those wrong turns to understand the problem space.
